
【概述】
优质的媒体内容是传统出版最大的优势。将这些内容进行数字出版,使内容的价值得到最大化,是传统出版与新媒体技术的强强联合。海量信息经过加工、整合、挖掘才能提升其使用价值,因此需要对书、刊、报、文档等电子出版物进行版面理解和版面分析,将版式文件转换为结构化XML,并建立数据之间的逻辑关系。
“全能图书结构化加工系统”是一个面向数字出版的图书内容结构化加工平台,将PDF等版式图书进行分析、拆分和标引,输出用XML描述的结构化数据,满足数字产品多元化发布的需要,例如专业知识数据库、流式电子书等,协助出版社从传统出版向数字出版快速打通技术瓶颈。
【平台特性】
1、全面的输入格式支持
- PDF:支持单层PDF、双层PDF。由于各种格式均可转为PDF,不需要为每种格式单独开发,就共享了PDF内容加工的所有特性。鉴于支持PDF至关重要,我们在系统中配备了三套PDF解析引擎,最大程度地兼容了各种PDF可能存在的问题。系统可以不依赖Acrobat独立运行。对PDF解析的正确性和效果可以达到Acrobat标准。
- PS:为了方便用户,和充分利用PS中版面结构信息,系统支持直接打开PS。支持的PS包括方正全系列(书版、维思、飞腾3、飞腾4、飞腾5、创艺、文合等)、华光全系列、以Adobe为代表的标准PS。能有效处理PS内嵌字体、内嵌图片、EPS图、艺术字、花边、图片裁剪、公式、字体映射等。无需另行提供页面图。
2、基于模板的自定义标引界面
- 自定义要标引的字段。
- 自定义标引字段的布局。
- 自定义字段控件类型,支持单选、多选、列表、文件、分类树、文本编辑、超文本编辑(支持字号、字体、样式调整)等。
3、全面的输出能力
- 支持输出主要的文件格式:包括TEXT、WORD、HTML、XML等。
- 自定义输出模板:根据不同的项目需要自定义输出模板,控制输出的内容和格式。
- 自定义输出文件名称及文件夹组织:可以按日期、版次、序号等变量来自动命名和层次化组织。
- 同时支持多种输出:一次反解标引,同时多种输出,满足多个需求。例如一种格式加载到数据库用于检索,另一种格式上传用于原版展示。
- 多种输出途径:本地文件及打包、HTTP上传、FTP上传、WEB Service上传、加载到数据库。
- 全面的输出内容:头版或封面的导读信息,目录链接信息;图片、文字、坐标等。
4、自动分析
- 版面分析(版面理解):利用版式数据中存在的版式信息,如:位置、字体、字号、颜色、辅助信息、版式风格等,辅以语义分析,提取版式数据的逻辑结构,将无序、无结构的数据,组织成有序、有结构的数据。 针对报纸版面:可以从复杂版面中提取必要的文字和排版信息,自动判定排版方向、合并正文块,自动还原正文阅读顺序,自动关联文章标题和正文,并进行附图与图说、文章与附图之间的自动关联。 针对图书版面:自动进行版心定位、页眉页脚和页码处理,自动进行目录提取、章节切分,进行参考文献等辅助信息的条目化处理。
- 文档结构识别:即文章或章节的分析。从书签、目录页或内容页进行分析,文章或章节的拆分,并生成目录信息。
- 格式分析:单词、行、段落的分析。PDF文件几乎没有格式信息,PS也经常缺乏完整的格式信息。本系统提供了一个高精度的格式分析算法。
- 文章或章节分析:从书签、目录页或内容页进行分析,文章或章节的拆分,并生成目录信息。
- 字段分析:报纸字段如标题、引题、副题、作者、来源等,期刊字段如标题、作者、作者单位、关键字、编号、内容摘要等,图书CIP元数据如书名、作者、责任编辑、出版单位、ISBN、开本、定价、发行单位、内容提要等。
5、高效的生产效率析
- 减少录入:默认值、可选值、值继承、全局字段、变量自动取值等。
- 自动查错:检查空值、唯一性、多值、正则表达式。
- 自动标引:通用关键字自动标引,基于简单规则的自动分类;也可以集成专业的自动分类、自动摘要组件。
- 备份恢复:一本书往往一次做不完,可以备份工作状态,下次恢复后继续。
- 多人协作:报纸版面大,时效性强,可以多人分工,分别处理不同版面;期刊、图书可以多人分工,分别处理不同部分。
- 连版的批量拆分。
- 自定义快捷键。
6、开放性、灵活性及可扩展性
可定制的标引方案、输出方案、分类法,多种上传方式,便于针对不同的数据或应用,快速定制,满足不同项目的需要,与不同系统进行配合。
【功能列表】
|
图书章节结构识别 |
可自定义识别规则。用于章节拆分和建立目录导航 |
|
图片识别 |
插图或废图识别,图题、图注与图片的关联 |
|
表格识别 |
三线或框线表格识别,表题、表注与表格关联。结构化表格输出。 |
|
排版格式识别 |
段落、空白等格式 |
|
页码识别 |
用于原版对照或建立索引项、目录项的定位等 |
|
版芯处理 |
过滤页眉、页脚、页边 |
|
文章拆分 |
可按指定的章节层次拆分文章 |
|
文章内部结构识别 |
如文章的作者、作者单位等 |
|
文章元数据标引及分类 |
经过标引和专业分类,提升信息附加值。可集成第三方数据挖掘模块(自动分类、摘要、抽取关键词等) |
|
索引处理 |
识别索引项,建立索引项定位 |
|
补字处理 |
补字的识别和表示 |
|
公式处理 |
公式的识别和表示 行内图处理 |
|
上、下标处理 |
上、下标的识别和表示 |
|
斜体、粗体、下划线 |
及更多的文字样式,更丰富的表现力 |
|
注释处理 |
注释识别和表示 脚注、尾注及其引用的双向链接 |
|
注音处理 |
|
|
英文处理 |
英文分词等 |
|
方正符号乱码 |
方正文件的英文、数字、标点乱码的自动纠正 |
【荣誉】
- 武汉大学信息管理学院数字出版系教学软件。
- 北京印刷学院数字出版实验室软件。
【成功案例】
- 人卫社:社内3-5位编辑负责预处理,发送加密数据到社外;社外30-50位兼职编辑(医学专业高校学生),负责精细加工和分类标引,回传加密数据到社内;社内解密后审核入库。资源应用为医学专业数据库产品,及苹果、亚马逊平台电子书出版。科技类图书,多为500-1000页,包含大量图、表、公式、上下标,多层章节结构。
- 人民社:社内5-10位编辑负责图书加工。资源应用为Kindle电子书阅读,及图书内容搜索。人文类图书,从PDF书签提取章节结构,有较多脚注、尾注需处理为双向链接。
- 电子社:社内3-10位编辑负责预处理及部分精品加工;在社外某学校建立加工部,20-30名操作员(学生),对加密数据进行精细加工;社内解密后审核入库。资源应用为IT专业数据库产品,及多平台电子书出版。科技、教育类图书,排版格式来源多,版式风格多样,加工结果符合DocBook标准。
【演示截图】
总体界面:

版面及排版格式分析:

章节结构分析:
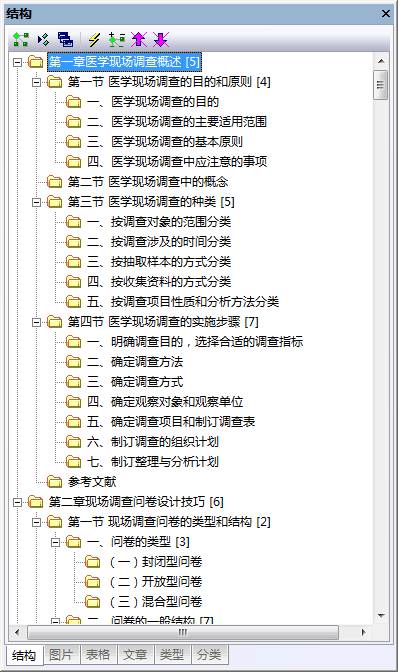 、
、
图片分析:
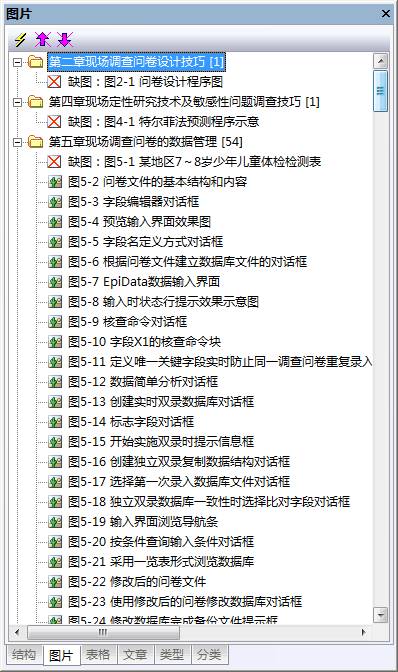
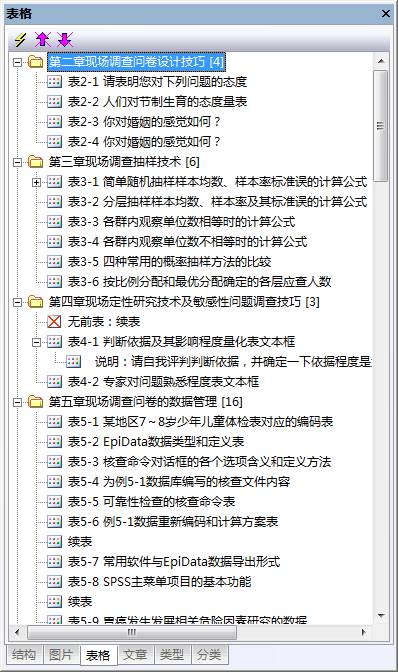
表格分析:
公式分析:

文章拆分:

文章标引:

文章分类:
